I’ve been already using LLMs for coding back in GPT-3 times – they were usable back then for simple mechanical tasks, but for nothing more. But now, especially with the release of o1 few months ago, they are very good.
Good enough that I’ve noticed I’m bottlenecked by user interface constraints (copying code to Claude/ChatGPT UI and back).
On the flip side, the recent reasoning models are slower than the previous ones. This means that if you don’t give models multiple tasks at once, you’ll be stuck waiting.
My new system (draft name “MLLM”) aims to solve both. The central entrypoint is a todo list:
- [1] add permission checks. manager users should be able to access everything and create CTFs. "guests" of a given ctf should also be able to access it.
files: ctfapp/views.py, ctfapp/models.py
- [2] DONE include CSRF token (in the way django expects) in all forms that do POST
files: ctfapp/views.py, ctfapp/models.py
- [3] make CTF details editable on CTF page. also make task details editable on task page
files: ctfapp/views.py, ctfapp/models.py
As you get new ideas for app features, you add them to the todo list.
You can then go to the system web UI:

From that UI, you can ask models to start working on your tasks (by clicking “start”), observe their progress and go to the details view:
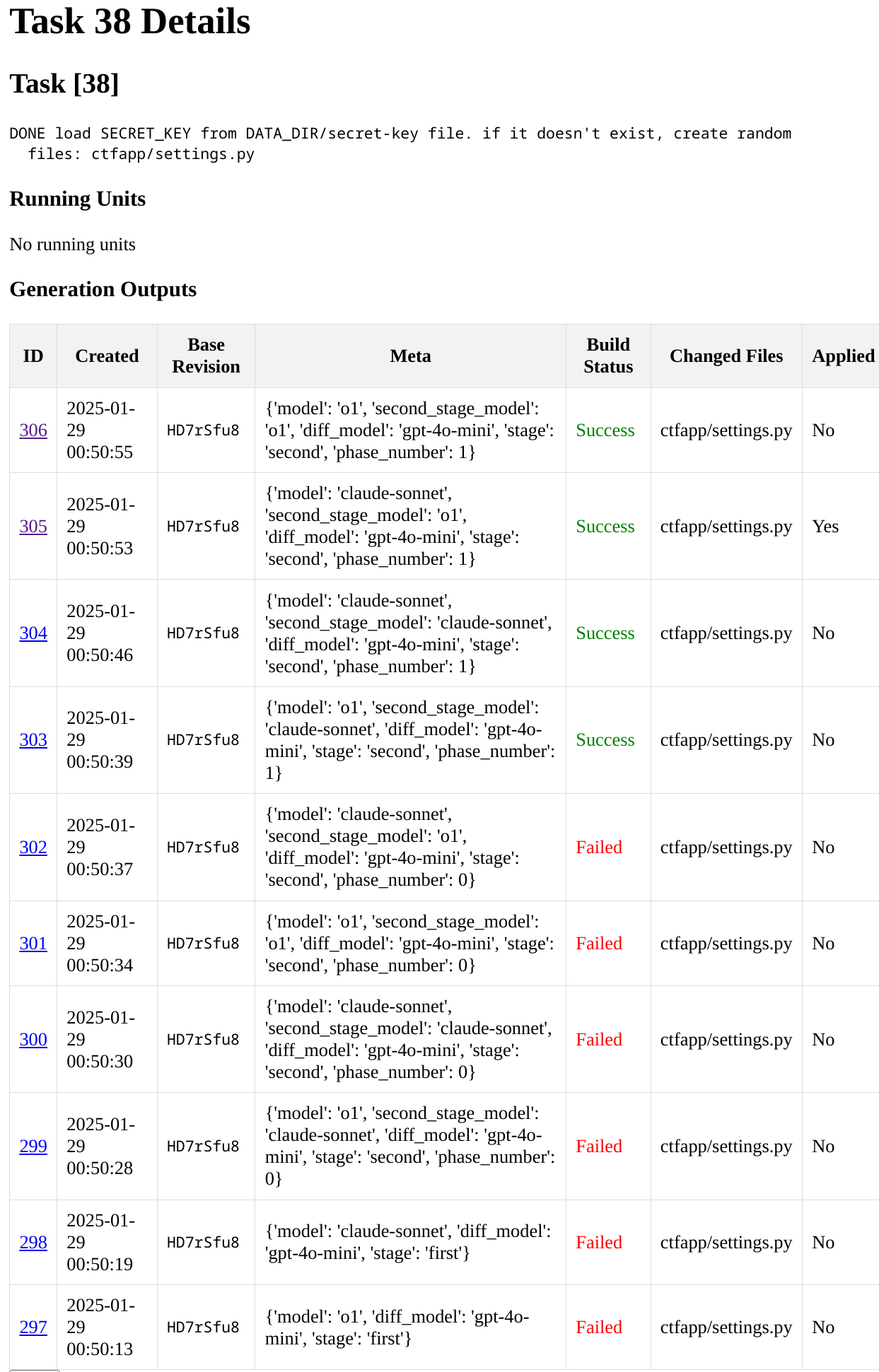
As you can see above, MLLM will run your prompt using multiple models. It will apply the diffs and then attempt to run your tests. If the tests fail, it will provide the feedback to the model and attempt again. In this case, none of the models could get it on the first try, but all eventually managed it on the second try.
As the next step in the workflow, you’ll browse through proposed diffs and choose which one to accept:
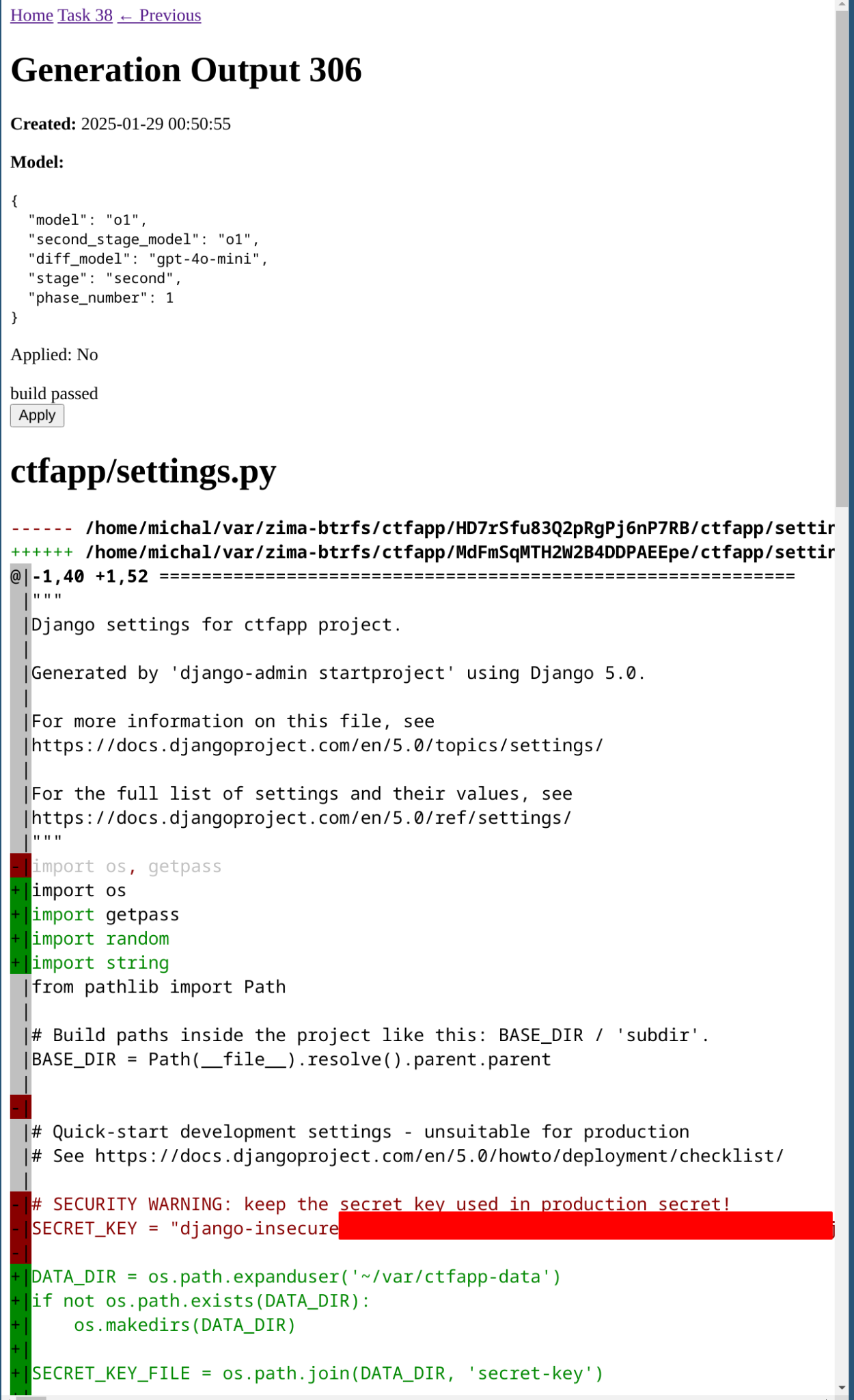
If you like none of them, you can always tweak your task prompt and run again.
How does this work under the hood?
When working on a task, the model simply combines a simple system prompt with the content of all files you have specified and your task prompt. Then, we ask a model to figure out a solution.
I call this the “reasoning phase”.
After this, we still need to apply the changes to the source files. These files can be quite large, so asking a large model will be expensive and slow (output tokens are more expensive than input tokens). Instead, we ask a smaller model (gpt-4o-mini) to generate the file based on the plan from the reasoning phase. Additionally we use OpenAI’s Predicted Output to reduce the latency.
We then apply these changes to a cloned version of your project (btrfs subvolumes are used to make this fast). Then, run your tests in a sandbox (based on bubblewrap).
Then, we continue the conversation by telling the models what diffs were applied. We also provide the build output to the model. This is useful for a couple of reasons:
-
models can fix errors based on test feedback
-
the chain of thought is longer overall with two iterations
-
we can use a different model for each iteration, allowing models to complement their strength (e.g. o1 is more intelligent, but Sonnet has better taste)
We save all these results into a Sqlite database, which is then used by the web UI. When the user clicks the “Apply” button, we do a three-way merge, in case the user has changed the file in the meantime.
The source code
The full source code is here: https://github.com/zielmicha/mllm
Right now, I didn’t really attempt to make it easy to run for anyone else than me. But let me know if you are interested, I might put some effort into it!